Today, I will show you how to install Hyper-V integration services in the Ubuntu Linux VM of Hyper-V. If the Hyper-V integration services are not installed, you cannot restore any data from Veeam Backup.
Today, I noticed two fresh vulnerabilities on the VBR12.1 Manager and console servers. Certain .net core requirements are installed when the product is installed. Unfortunately, The .net isn’t patched automatically through Windows updates.
Veeam Backup & Replication 12.1 is the newer build of version 12, and the major new features and enhancements were added in Veeam Backup & Replication v12.1. e.g. Detect and identify cyber threats, Respond and recover faster from malware, Ensure security and compliance, Veeam App for ServiceNow, Backup of object storage, Veeam CDP enhancements, Veeam AI Assistant, etc.
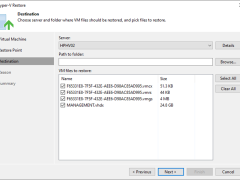
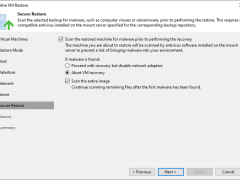
You can restore VM files (XML, VMCX, VMRS, VMGS, VHD, VHDX) if they become corrupted. This option is an excellent alternative to restoring the entire VM. You can only restore a single VM file.
Existing jobs do not need to be updated that process the original/recovered VMs if you restore them to the same host and choose to preserve VM UUIDs. If you configure restore differently and want to process the recovered VMs, you must edit existing jobs or create new ones.
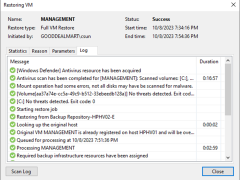
If the original VM fails, you can use Veeam Backup & Replication to restore an entire VM from a backup file to the most recent state or a previous point.
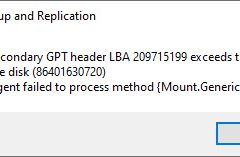
VBR v12 guest file restore—happen error message is as below:
Secondary GPT header LBA 209715199 exceeds the size of the disk (86401630720)
Agent failed to process method {Mount.GenericMount)
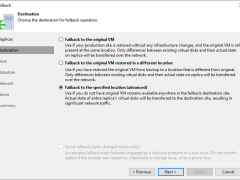
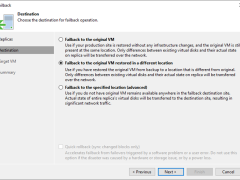
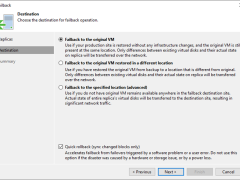
For the Failback to the specified location, Veeam Backup & Replication must transfer the entire VM data, including its configuration and virtual disc content. Choose this option if you cannot use the original VM or restore it from a backup.
Because Veeam Backup & Replication only needs to transfer differences between the original/recovered VM and VM replica, the failback to the original virtual machine restored in a different location option helps reduce recovery time and network traffic.
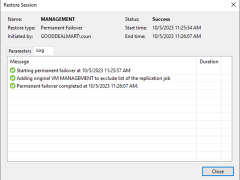
Failback is returning operations to the primary site after a disaster recovery event. It reverses the failover process by replicating any changes made to the virtual machine during the Failover state back to the primary site and then redirecting users and applications back to the primary site.
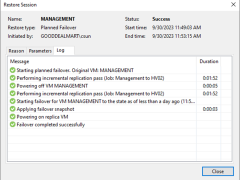
Planned failover is the smooth manual switching from a primary VM to its replica with minor downtime. Planned failover is proper when you know primary VMs are planning to go offline, and you need to switch the workload from the original VMs to their replicas as soon as possible. For example, you can use planned failover to perform data center migration, maintenance, or software upgrades on primary VMs. You can also perform planned failover if you see signs of an impending disaster.
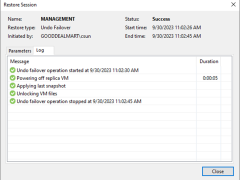
One method for completing failover is to use failover undo. When you undo failover, you return to the original VM from a VM replica. When a virtual machine replica is in the Failover state, Veeam Backup & Replication discards all changes made to the replica. This is because the Failover state is intended to be a temporary state used to restore the virtual machine to operation quickly in the event of a disaster.
Failing over a virtual machine to a disaster recovery site involves replicating the virtual machine and its data to the disaster recovery site and then activating the replicated copy in the event of a disaster or other disruptive event that renders the original virtual machine unavailable.
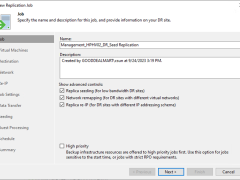
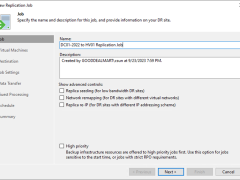
This procedure creates a replication job with seeding to replicate the specified VMs to the disaster recovery site. If a disaster strikes and the production VM stops working properly, you can fail over to its replica.
This procedure creates a replication job to replicate the specified VMs to the disaster recovery site. If a disaster strikes and the production VM stops working properly, you can fail over to its replica.
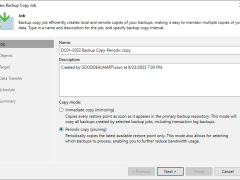
Periodic copy jobs can be scheduled to run during non-business hours or low-activity periods, reducing the impact on production systems. This allows you to efficiently manage backup and copy operations without causing disruption.
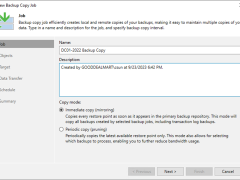
Immediate copies help reduce your RPO, which is the maximum allowable data loss in the event of a disaster. By creating copies as soon as new data is backed up, you ensure that your data loss is minimal.